
A Stratum 1 Time Server – The Basics
A while ago, I decided to play around with trying to create something cheap that would be able to synchronise its time by using GPS instead of over the internet – essentially building my own Stratum 1 time server. I intend this to be a series of articles about NTP and time servers, but let’s start with the basics…
What is a Stratum 1 Time Server?
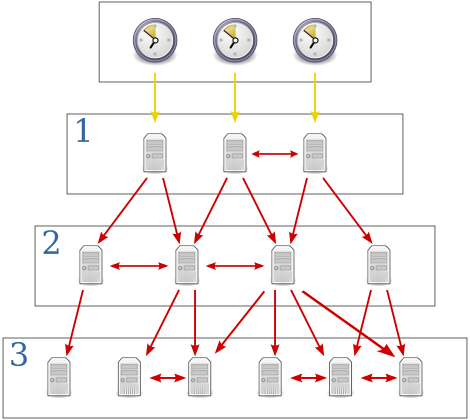 The lower the “Stratum” number the more accurate the time it should be able to tell. Usually Stratum 1 time servers are directly connected to an accurate source of time such as (but not limited to) Atomic, GPS or even Radio clocks. The stratum of the machine which itself is directly interfacing with the accurate time source would be “Stratum 0”. For each additional layer of NTP servers added, the stratum increases by 1.
The lower the “Stratum” number the more accurate the time it should be able to tell. Usually Stratum 1 time servers are directly connected to an accurate source of time such as (but not limited to) Atomic, GPS or even Radio clocks. The stratum of the machine which itself is directly interfacing with the accurate time source would be “Stratum 0”. For each additional layer of NTP servers added, the stratum increases by 1.
So if the server that’s connected directly to the time source is stratum 0, it would appear to any clients who want to synchronise with it as a stratum 1 source. If someone then tries to synchronise to one of those, they would see a stratum 2 source and so on. The image on the right illustrates the top-down increase in stratum and was taken from Wikipedia.
Generally the higher the stratum number, the less-accurate its view of time is. A stratum ranges from stratum 1 all the way to stratum 15 indicating the time is getting further away from a reference clock the higher you go. Stratum 16 indicates the clock is pretty far from the reference and should be considered un-synchronised and should not be used.
Why do we need time servers?
Every computer out there – be it a desktop, laptop, server or otherwise usually need to keep track of the time one way or the other. Computers usually have dedicated hardware to keep track of the time (notable exceptions are Raspberry Pis), some of which are more accurate than others but ultimately each one is different.
To demonstrate how computers can’t keep track of accurate time on their own, I rigged up 2 machines and synchronised their clocks to the same time server. Once initially synchronised I simply left them to run for 8 hours to see how much their view of time has drifted away from what the time server suggests is correct. This test was completed without ntpd creating a drift file (more on that later)
One thing note here is that the Pis clock is running faster than the reference clock, whereas the laptop is actually running slower.
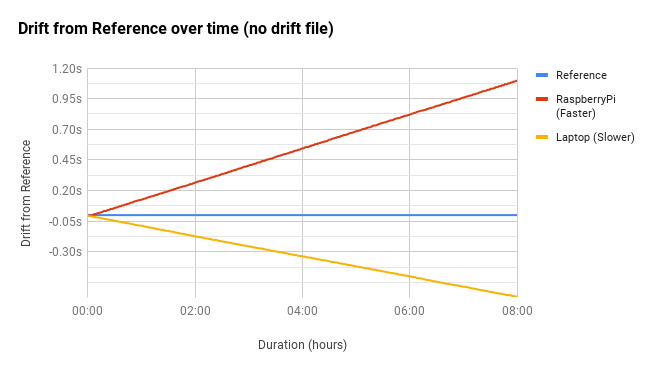
This clearly shows that over just 8 hours, there’s a significant discrepancy between the two machine’s local clocks vs what the time actually is. Obviously the longer they remain un-synchronised, the larger the drift becomes.
How do I deal with time drift?
On Linux, running ntpd has the advantage of having some sophisticated features and algorithms behind it designed to keep your local clock as accurate as possible.
Once ntpd has been running for a while (and has been able to successfully synchronise time with an external source) it’s able to estimate the inherent drift of your local clock and compensate for it accordingly.
The drift itself is called “frequency error”. Calculating it is a process that continuously happens in the background, which ultimately results in the generation of a “drift file”. This file is used to compensate for drift when ntpd starts up next so it doesn’t have to go through the initial learning process again.
Once it had determined the frequency error for my two test machines, I ran the same test we did earlier to see how well ntpd coped with clock drift.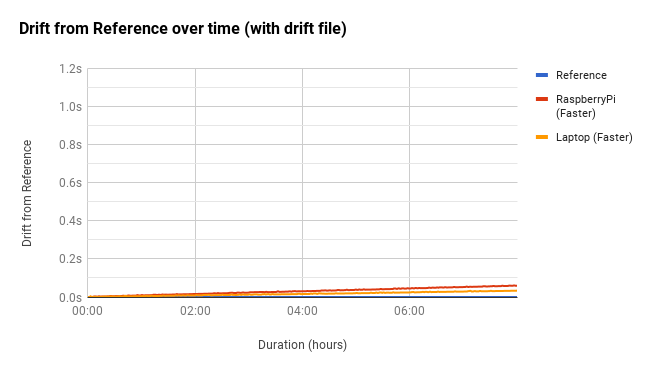 As you can see from the above graph (kept at the same scale), we’ve easily managed to keep drift on both machines to within 0.1s of our reference clock. You’ll notice however that both clocks are now running faster than our reference…
As you can see from the above graph (kept at the same scale), we’ve easily managed to keep drift on both machines to within 0.1s of our reference clock. You’ll notice however that both clocks are now running faster than our reference…
Environmental conditions affect your computers ability to track time, as does system load and even power fluctuations from your utility provider. This means that if you were to monitor the frequency error reported by ntpd, you’d see that it can fluctuate quite a bit; You’ll likely never be able to get a stable frequency error so will likely never get 100% perfect time-keeping without help, but its a damn good start and a large improvement over having no clock discipline at all!
So, where do I start?
Most default installs for ntpd come pre-configured with servers from the NTP Pool Project so as long as you’re running ntpd then you should be OK.
You can check the current status of ntpd by querying the local machine for its list of peers by using ntpq -pn
# ntpq -pn
remote refid st t when poll reach delay offset jitter
==============================================================================
*85.199.214.99 .GPS. 1 u 32 64 377 8.406 -0.147 0.073
-138.68.151.69 194.117.9.136 3 u 38 1024 377 5.835 2.372 15.680
+129.250.35.250 249.224.99.213 2 u 1052 1024 377 6.587 0.666 0.139
+80.87.131.131 80.87.128.222 4 u 442 1024 377 22.322 -0.635 0.270
This output shows some useful information so lets work through it (Taken from http://nlug.ml1.co.uk/2012/01/ntpq-p-output/831 where more detailed descriptions of this output can be found)
- remote – The remote peer or server being synced to
- refid – Where or what the remote peer or server is itself synchronised to
- st – The remote peer or server Stratum (from our point of view)
- t – Type (u: unicast or manycast, b: broadcast or multicast, l: local reference clock, s: symmetric peer, A: manycast server, B: broadcast server, M: multicast server)
- when – When last polled (seconds ago, “h” hours ago, or “d” days ago)
- poll – Polling frequency
- reach – An 8-bit left-shift shift register value recording polls (bit set = successful, bit reset = fail) displayed in octal
- delay – Round trip communication delay to the remote peer or server (milliseconds)
- offset – Mean offset (phase) in the times reported between this local host and the remote peer or server (milliseconds)
- jitter – Mean deviation (jitter) in the time reported for that remote peer or server (miliseconds)
What does all that ACTUALLY mean?
Looking at what we have above – we’re using 85.199.214.99 as our primary time source (signified by the *). That server is getting its time direct from a GPS clock and so is a stratum 1 server. Its reported time differs from what we think the current time is by only 0.147ms (we’re running faster than it).
The stratum 2 and 4 servers are also pretty close with their offset so are potential candidates to synchronise time with if the current stratum 1 server goes offline. ntpd will automatically choose which server to synchronise from and will also weed out ones that are seemingly reporting bad time by comparing it with the other servers loaded. If you’re using a configuration which makes use of the NTP pool then the servers that appear will likely be different each time you start ntpd.
A big thanks goes to the volunteers at the NTP Pool Project for making it possible without running your own infrastructure!
This article should hopefully have given you a bit more insight as to why time servers are needed. In the future I plan to explore setting up a local NTP server to use with a view of getting our own GPS timing device hooked up and working.